Linux Capability - A Kernel Walkthrough
Table of Contents
*The kernel excerpts were from v5.1 rc2. I became interested in this topic while I was learning container isolation. Back then I had a difficult time trying to understand how capabilities and SELinux work together, then accidentally stumble on the fact that both are built on top of Linux Security Module(LSM). And here’s the rabbit hole that I dug.
What is the Capability? #
The traditional way of Linux performing permission checks was pretty coarse. Before kernel 2.2, Linux had only two types of processes. The privileged process whose effective user ID (euid) is 0 and the unprivileged whose uid is non-zero. Needless to say the all-eggs-in-one-bucket approach can be risky. For instance, you have to grant privileged permission (aka. “root”) to a process who need to listen to a system port (0-1024). However by doing so, you also gives the process the right to read all filesystems, change password, load kernel modules etc.
To ensure a privileged process only get the minimum set of privilege required, Linux has introduced the capability mechanism which further divides the “root” privilege into dozens of “capabilities”. The full list of available capabilities is defined in include/linux/capability.h.
Capability is a per-threat and per-file attribute defined as a 64-bit mask. For instance, CAP_NET_RAW 13 in capability.h means the flag is at 13th bit. Flip the bit then you will get the subset of superpower below.
/* Allow use of RAW sockets */
/* Allow use of PACKET sockets */
/* Allow binding to any address for transparent proxying (also via NET_ADMIN) */
#define CAP_NET_RAW 13
For processes, the capability is inherited from the parent process at fork() time. One interesting fact is that given the set of the parent process’ capability, the child process can only drop some but never could add in more. Imagine a web server process with CAP_NET_RAW capability forked many children to handle concurrent requests. This mechanism guaranteens the child processes can only do less than their parents, so as to ensure the capability’s rule are properly obeyed.
For files, the capability is implemented as an extended file attribute. You can define additional capabilities to be added to a process during exec() time. This can come in handy if you need to grant an executable only the minimum set of permission it needs instead of blindly running it as root. Liz Rice has given a nice example in her Container Security book:
vagrant@vagrant:~$ cp /bin/ping ./myping
vagrant@vagrant:~$ ls -l myping
-rwxr-xr-x 1 vagrant vagrant 64424 Feb 12 18:18 myping
vagrant@vagrant:~$ ./myping 10.0.0.1
ping: socket: Operation not permitted
vagrant@vagrant:~$ sudo setcap 'cap_net_raw+p' ./myping
vagrant@vagrant:~$ ls -l myping
-rwxr-xr-x 1 vagrant vagrant 64424 Feb 12 18:18 myping
vagrant@vagrant:~$ getcap ./myping
./myping = cap_net_raw+p
vagrant@vagrant:~$ ./myping 10.0.0.1
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
^C
To consolidate what we have discussed so far, let us take containerd as an example. You can view a process’ current capability under /proc/[pid]/status. For the rest of the discussion, we will only be using CapEff which represent the effective (actual) capability of a process.
$ ps ax|grep containerd
642302 ? Ssl 36:40 /usr/bin/containerd
$ cat /proc/642302/status | grep Cap
CapInh: 0000000000000000
CapPrm: 0000003fffffffff
CapEff: 0000003fffffffff
CapBnd: 0000003fffffffff
CapAmb: 0000000000000000
# use capsh to decode the bit mask
~$ capsh --decode=0000003fffffffff
0x0000003fffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read
(This is still an overly simplified narrative, but sufficient to carry us along with the conversation. To find out more, google search the difference in three capability sets i.e. permitted/effective/ inheritable and how they differ when being applied to processes and files. )
Case Study Part 1 - Socket Creation and CAP_NET_RAW #
To really understand what’s going on under the hood, we need to dive into the kernel.
Assume we want to ping 8.8.8.8, as you have seen before, the ping program needs to open a socket. In the kernel, socket creation is handled by inet_create().
linux/net/ipv4/af_inet.c
/*
* Create an inet socket.
*/
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
...
if (sock->type == SOCK_RAW && !kern &&
!ns_capable(net->user_ns, CAP_NET_RAW))
goto out_rcu_unlock;
...
out:
return err;
out_rcu_unlock:
rcu_read_unlock();
goto out;
}
Notice that before a socket is created, the function calls ns_capable to check if the process has CAP_NET_RAW capability. Here ns refers to the user namespace(https://man7.org/linux/man-pages/man7/user_namespaces.7.html) of the process.
This may seem confusing at first since we know capability is an attribute of a PROCESS. This is true until the user namespace is introduced. When a process is added to a new user namespace, it is allowed to have a different identifier (e.g. uid and guid), the root directory, and capabilities. The name of ns_capable simply highlights the fact that the function is namespace-compatible.
linux/kernel/capability.c
/**
* ns_capable - Determine if the current task has a superior capability in effect
* @ns: The usernamespace we want the capability in
* @cap: The capability to be tested for
*
* Return true if the current task has the given superior capability currently
* available for use, false if not.
*
* This sets PF_SUPERPRIV on the task if the capability is available on the
* assumption that it's about to be used.
*/
bool ns_capable(struct user_namespace *ns, int cap)
{
return ns_capable_common(ns, cap, CAP_OPT_NONE);
}
EXPORT_SYMBOL(ns_capable);
static bool ns_capable_common(struct user_namespace *ns,
int cap,
unsigned int opts)
{
int capable;
if (unlikely(!cap_valid(cap))) {
pr_crit("capable() called with invalid cap=%u\n", cap);
BUG();
}
capable = security_capable(current_cred(), ns, cap, opts);
if (capable == 0) {
current->flags |= PF_SUPERPRIV;
return true;
}
return false;
}
#define cap_valid(x) ((x) >= 0 && (x) <= CAP_LAST_CAP)
Following the chain of calls, we will end up in ns_capable_common. The logic is straight forward: if the process passes security_capable() checks, it will add a flag PF_SUPERPRIV(meaning “Used super-user privileges”) to the current process and return true (which allows the socket creation process to continue).
linux/security/security.c
int security_capable(const struct cred *cred,
struct user_namespace *ns,
int cap,
unsigned int opts)
{
return call_int_hook(capable, 0, cred, ns, cap, opts);
}
#define call_int_hook(FUNC, IRC, ...) ({ \
int RC = IRC; \
do { \
struct security_hook_list *P; \
\
hlist_for_each_entry(P, &security_hook_heads.FUNC, list) { \
RC = P->hook.FUNC(__VA_ARGS__); \
if (RC != 0) \
break; \
} \
} while (0); \
RC; \
})
However, things start to get fuzzy when entering security_capable(). The logic of call_int_hook roughly means, to check whether the process has permission cap (i.e. CAP_NET_RAW), it will call a bunch of functions (i.e. “security checks”) in the hlist &security_hook_heads.capable one by one, until all security checks have passed.
The weird hook structure is a direct by-product of Linux Security Module(LSM) adoption. To truly understand what is going on here, we will have to take a short detour to LSM.
Case Study Part 2 - A Detour to LSM Hooks #
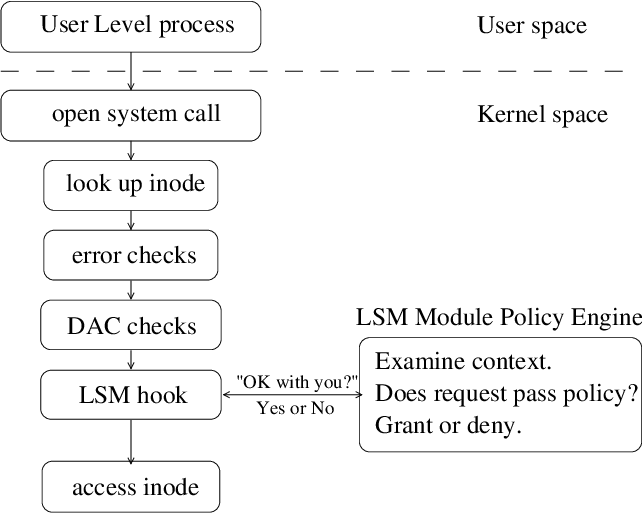
LSM Hook Architecture [Source]
LSM was born shortly after SELinux’s birth in 2001. It was a chaotic period where Linux has yet to build a unified security model. To give Linux the flexibility to plug in and play any security control systems, Crispin Cowan proposed LSM. LSM provides a generic framework for developers to implement security policies which now forms the foundation of capability, SELinux, and AppArmor.
The idea of LSM is simple. To enforce security policies is mostly equivalent to set up interception points in the middle of key kernel functions (such as inet_create for socket creation). The function should only be allowed to continue if a security check has passed.
In layman’s terms, LSM is like the station for sentries. It sets up empty stations (hooks such as ns_capable in inet_create) in those critical passageways (kernel functions). If later on we want to plug in a security policy module, be it capability or SELinux, it is equivalent to send a “capability” sentry or “SELinux” sentry into the station. Whenever a car passes through the checkpoint (function call), the sentries will go in one by one to determine if this car is legal. If all sentries (note we can have multiple LSM modules work simultaneously) reach a consensus on passing, the car or the function then can be let go.
Under the hood, each “station”/hook is a hlist structure that holds a list of registered callback functions. The callback function is wrapped in a struct security_hook_list. While the struct’s calls itself a “list”, it is in fact, a hlist node on its own.
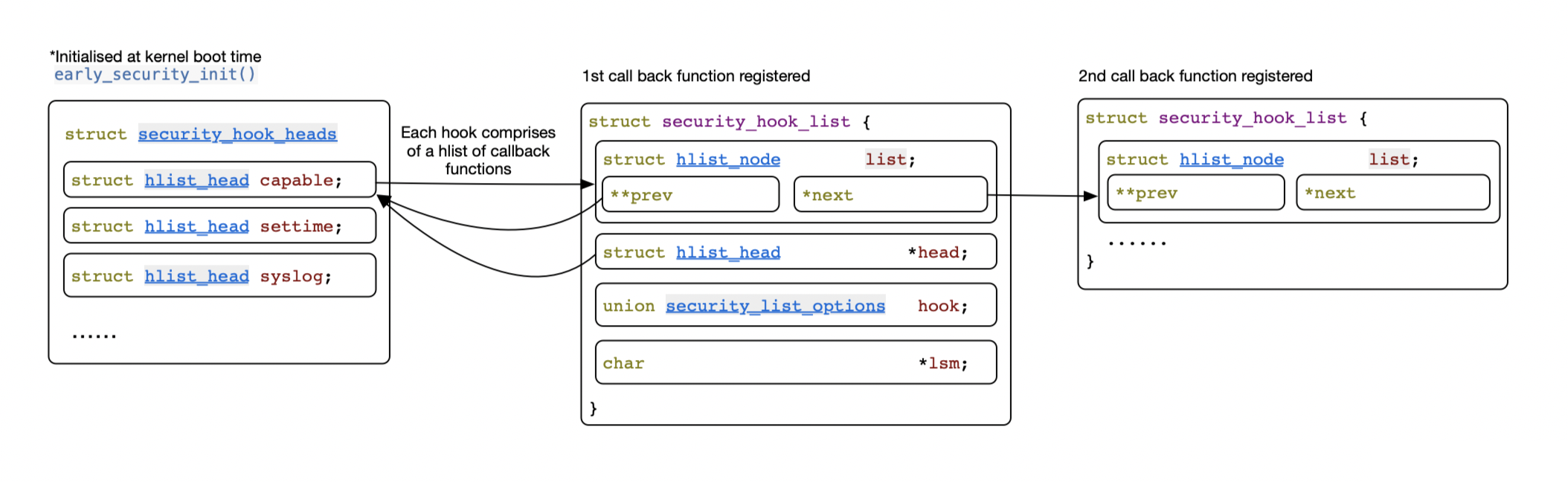
This isn’t the full picture yet. How does capability register its hooks?
To answer that, we will have to jump to linux/security/commoncap.c. Here capability_hooks[] defines a list of target LSM hooks. For each hook, it provides a callback function to be registered. Each of the pair is a security_hook_list struct (don’t let the word “list” bother you, think of it as a tuple) initialised by LSM_HOOK_INIT. Soon later security_add_hooks() goes through the list and appends each of the callback to its corresponding hook point as a hlist node.
linux/include/linux/lsm_hooks.h
/*
* Security module hook list structure.
* For use with generic list macros for common operations.
*/
struct security_hook_list {
struct hlist_node list;
struct hlist_head *head;
union security_list_options hook;
char *lsm;
} __randomize_layout;
linux/security/commoncap.c
#ifdef CONFIG_SECURITY
struct security_hook_list capability_hooks[] __lsm_ro_after_init = {
LSM_HOOK_INIT(capable, cap_capable),
LSM_HOOK_INIT(settime, cap_settime),
LSM_HOOK_INIT(ptrace_access_check, cap_ptrace_access_check),
LSM_HOOK_INIT(ptrace_traceme, cap_ptrace_traceme),
LSM_HOOK_INIT(capget, cap_capget),
LSM_HOOK_INIT(capset, cap_capset),
LSM_HOOK_INIT(bprm_set_creds, cap_bprm_set_creds),
LSM_HOOK_INIT(inode_need_killpriv, cap_inode_need_killpriv),
LSM_HOOK_INIT(inode_killpriv, cap_inode_killpriv),
LSM_HOOK_INIT(inode_getsecurity, cap_inode_getsecurity),
LSM_HOOK_INIT(mmap_addr, cap_mmap_addr),
LSM_HOOK_INIT(mmap_file, cap_mmap_file),
LSM_HOOK_INIT(task_fix_setuid, cap_task_fix_setuid),
LSM_HOOK_INIT(task_prctl, cap_task_prctl),
LSM_HOOK_INIT(task_setscheduler, cap_task_setscheduler),
LSM_HOOK_INIT(task_setioprio, cap_task_setioprio),
LSM_HOOK_INIT(task_setnice, cap_task_setnice),
LSM_HOOK_INIT(vm_enough_memory, cap_vm_enough_memory),
};
static int __init capability_init(void)
{
security_add_hooks(capability_hooks, ARRAY_SIZE(capability_hooks),
"capability");
return 0;
}
DEFINE_LSM(capability) = {
.name = "capability",
.order = LSM_ORDER_FIRST,
.init = capability_init,
};
#endif /* CONFIG_SECURITY */
void __init security_add_hooks(struct security_hook_list *hooks, int count,
char *lsm)
{
int i;
for (i = 0; i < count; i++) {
hooks[i].lsm = lsm;
hlist_add_tail_rcu(&hooks[i].list, hooks[i].head);
}
if (lsm_append(lsm, &lsm_names) < 0)
panic("%s - Cannot get early memory.\n", __func__);
}
The LSM_HOOK_INIT macro worths some extra notes. In our above example, the macro expands to { .head = &security_hook_heads.capable, .hook = { .capable = cap_capable } } which initialises the security_hook_list struct. Notice .lsm and .list are both uninitialised at the moment. .list itself will later become a node of the hlist capable in security_hook_heads.
/*
* Initializing a security_hook_list structure takes
* up a lot of space in a source file. This macro takes
* care of the common case and reduces the amount of
* text involved.
*/
#define LSM_HOOK_INIT(HEAD, HOOK) \
{ .head = &security_hook_heads.HEAD, .hook = { .HEAD = HOOK } }
union security_list_options {
int (*binder_set_context_mgr)(struct task_struct *mgr);
int (*binder_transaction)(struct task_struct *from,
struct task_struct *to);
...
int (*capable)(const struct cred *cred,
struct user_namespace *ns,
int cap,
unsigned int opts);
...
}
That’s it. With the understanding of the LSM hook architecture, if you look back at call_int_hook(), the logic will make much more sense now.
Case Study Part 3 - Checking Capabilities #
Remember we are still in the mid of the ping example. Continue from part 1 where we were at call_int_hook() , the control flow finally reaches cap_capable() which is the actual function that does the capability checks.
While the whole user namespace complications worth another full blog to explain, we can focus on capability itself for now. The gist of the code is at cap_raised which compares the required cap with the effective cap of the process by doing a bit-wise AND. Once done checking, the function returns 0 and this will eventually let inet_create() continue.
linux/security/commoncap.c
/**
* cap_capable - Determine whether a task has a particular effective capability
* @cred: The credentials to use
* @ns: The user namespace in which we need the capability
* @cap: The capability to check for
* @opts: Bitmask of options defined in include/linux/security.h
*
* Determine whether the nominated task has the specified capability amongst
* its effective set, returning 0 if it does, -ve if it does not.
*
* NOTE WELL: cap_has_capability() cannot be used like the kernel's capable()
* and has_capability() functions. That is, it has the reverse semantics:
* cap_has_capability() returns 0 when a task has a capability, but the
* kernel's capable() and has_capability() returns 1 for this case.
*/
int cap_capable(const struct cred *cred, struct user_namespace *targ_ns,
int cap, unsigned int opts)
{
struct user_namespace *ns = targ_ns;
/* See if cred has the capability in the target user namespace
* by examining the target user namespace and all of the target
* user namespace's parents.
*/
for (;;) {
/* Do we have the necessary capabilities? */
if (ns == cred->user_ns)
return cap_raised(cred->cap_effective, cap) ? 0 : -EPERM;
/*
* If we're already at a lower level than we're looking for,
* we're done searching.
*/
if (ns->level <= cred->user_ns->level)
return -EPERM;
/*
* The owner of the user namespace in the parent of the
* user namespace has all caps.
*/
if ((ns->parent == cred->user_ns) && uid_eq(ns->owner, cred->euid))
return 0;
/*
* If you have a capability in a parent user ns, then you have
* it over all children user namespaces as well.
*/
ns = ns->parent;
}
/* We never get here */
}
linux/include/linux/capability.h
#define cap_raise(c, flag) ((c).cap[CAP_TO_INDEX(flag)] |= CAP_TO_MASK(flag))
#define cap_lower(c, flag) ((c).cap[CAP_TO_INDEX(flag)] &= ~CAP_TO_MASK(flag))
#define cap_raised(c, flag) ((c).cap[CAP_TO_INDEX(flag)] & CAP_TO_MASK(flag))
/*
* Bit location of each capability (used by user-space library and kernel)
*/
#define CAP_TO_INDEX(x) ((x) >> 5) /* 1 << 5 == bits in __u32 */
#define CAP_TO_MASK(x) (1 << ((x) & 31)) /* mask for indexed __u32 */
Reference #
LSM Design: Mediate Access to Kernel Objects
Linux Security Modules (Part 1)
https://thibaut.sautereau.fr/2017/05/26/linux-security-modules-part-1/
Introduction of LSM Framework
https://liwugang.github.io/2020/10/18/introduce_lsm.html#lsm-初始化