CVE-2017-16995 Analysis - eBPF Sign Extension LPE
Table of Contents
eBPF Background #
eBPF(Enhanced Berkeley Packet Filter) is an in-kernel virtual machine that is used as an interface to data link layers, allowing packets on the network to be filtered by rules. A userspace process will supply a filter program to specify which packets it wants to receive and eBPF will return packets that pass its filtering process.
Each BPF memory instructions are made up of 64 bits (8 bytes). 8 bits for opcode, 4 bits for source register, 4 bits for destination register, 16 bits for offset and 32 bits for immediate value.
eBPF consists of 10 64-bit register known as r0 - r10. r0 stores the return value, r1 to r5 is reserved for arguments, r6 to r9 is reserved for storing callee saved registers and r10 stores read-only frame pointer.
In order to keep state between invocations of eBPF programs, allow sharing data between eBPF kernel programs and also between kernel and user-space applications, eBPF utilizes different types of maps in the form of key-value pair. Two bpf functions, BPF_MAP_LOOKUP_ELEM and BPF_MAP_UPDATE_ELEM , are provided to facilitate sharing of data between programs.
Overview #
CVSS v3 Score: 7.8
Confidentiality: High
Integrity: High
Authority: High
The vulnerability is caused by a sign extension from a signed 32-bit integer to an unsigned 64-bit integer, bypassing eBPF verifier and leading to local privilege escalation.
Before each of the BPF program runs, two passes of verifications are conducted to ensure its correctness. The first pass check_cfg() ensures the code is loop-free using depth-first search. The second pass do_check() runs a static analysis to emulate the execution of all possible paths derived from the first instruction. The program will be terminated if any invalid instruction or memory violation is found.
In the exploit, a set of BPF instructions are carefully crafted to bypass this filtering process through an unintentional sign extension from 32 bits to 64 bits. As a result, a few lines of malicious code attached managed to execute in the kernel space, resulting in privilege escalation.
This vulnerability allows attacker to have full control of the system with root access. The low complexity of the attack and low privileges required to perform this exploit makes it a high priority to fix.
Code Analysis #
1. eBPF Instruction Set #
User-supplied eBPF programs are written in a special machine language that runs on the eBPF virtual machine. The VM follows the generic Reduced Instruction Set Computer(RISC) design and has 10 general purpose registers and several named registers.
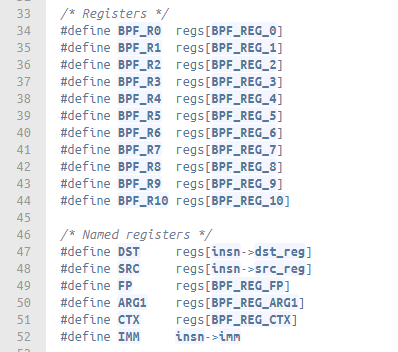
fig 3.1 Register Definitions in the eBPF VM, from /kernel/bpf/core.c
Each BPF instruction on x64 platform is of 64-bit long. They are internally represented by a bpf_insn struct which contains the following fields (fig 3.2). Given the limited size of the opcode field, instructions are categorised into 8 classes(fig 3.3). For instance, BPF_MOV shares the same opcode with BPF_ALU64 and BPF_X by definition(fig 3.4).

fig 3.2 Structure of a BPF instruction, from /include/uapi/linux/bpf.h
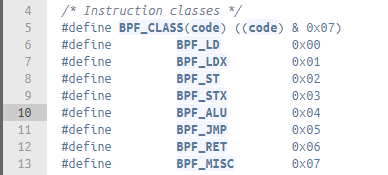
fig 3.3 BPF instruction classes, from /include/uapi/linux/bpf_common.h
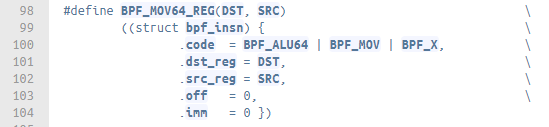
fig 3.4 Definition of BPF_MOV64_REG, from /include/linux/filter.h
2. Source Code Analysis #
The exploit of CVE-2017-16995 boils down to a mere 40 eBPF instructions. We will be focusing on the first two instructions because they are mainly used to bypass the verification mechanism of eBPF.
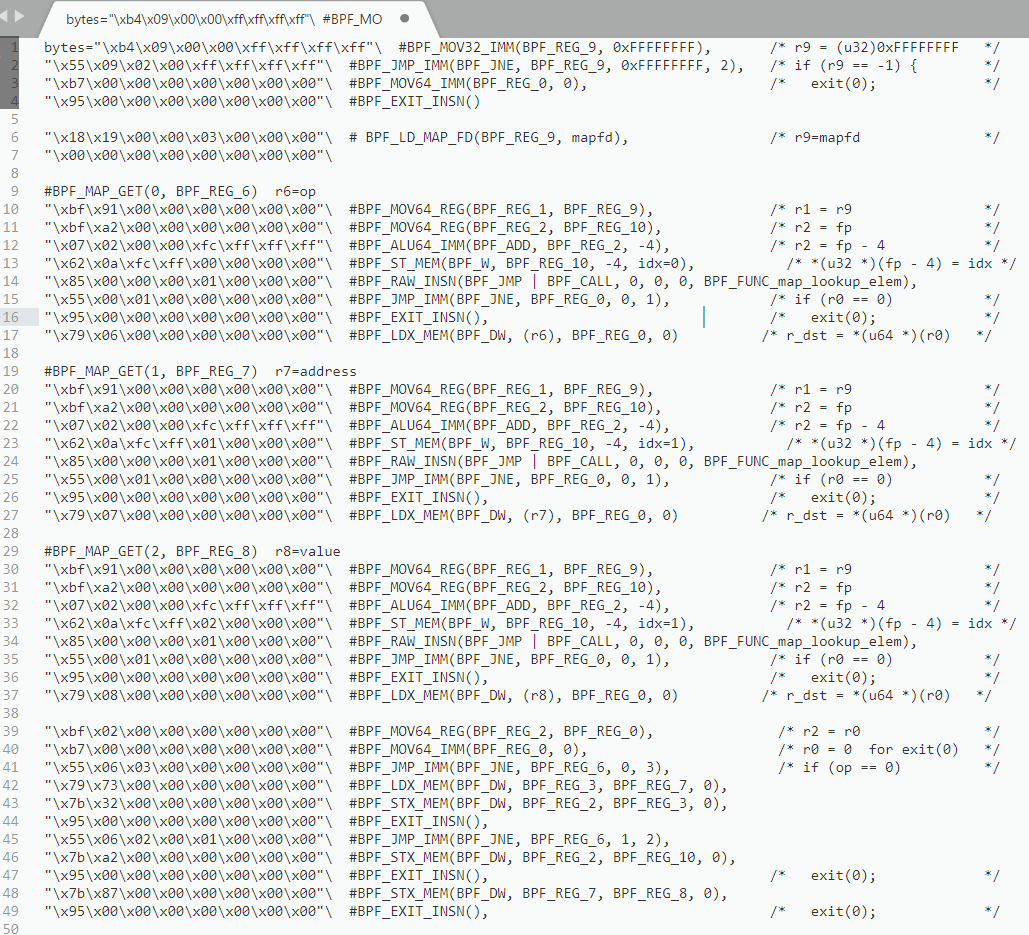
As mentioned before, eBPF performs a two round verification before actually running the user-supplied code. For this CVE we are only interested in second round check which is done in the do_check() function. When the first instruction BEF_MOV32_IMM is evaluated, it is passed to check_alu_op() to process since BEF_MOV32_IMM belongs to the BPF_ALU group (fig 3.6). The immediate value (0xFFFFFFFF) from the first instruction is then stored in the register BPF_REG_9 (fig 3.7).

fig 3.6 do_check(), from /kernel/bpf/verifier.c
fig 3.7 check_alu_op() from /kernel/bpf/verifier.c
To make things clearer, we can take a look at how registers in eBPF are represented. The registered are stored in an array of structs named reg_state. The immediate value 0xFFFFFFFF is stored in a 64-bit int imm, which becomes 0x00000000FFFFFFFF in memory.

fig 3.8 struct reg_state, from /kernel/bpf/verifier.c
Now the second instruction BPF_JMP_IMM(BPF_JNE, BPF_REG_9, 0xFFFFFFFF, 2) is evaluated. The instruction compares the immediate value 0xFFFFFFFF with the content inside BPF_REG_9, and jump to the place that is 2 instructions away if the two values do not equal.
This time do_check() calls check_cond_jmp_op() to check for both type and value in dst_reg, which is BPF_REG_9 in this case (fig. 3.9). Clearly (int)0x00000000FFFFFFFF = (s32)0xFFFFFFFF and opcode != JEQ, it falls under the case imm != imm and the jump is not performed. The program continues until it hits BPF_EXIT_INST() on line 4 and exit.
fig 3.9 check_cond_jmp_op(), from /kernel/bpf/verifier.c
Usually, the eBPF verifier uses a stack to keep tracking branches that have not been evaluated and revise them later(fig 3.9, line 1236). However, since the integer comparison on line 1220 always equals, the code continue from line 1232 and the other branch is never pushed to the stack.
When the verifier evaluate BPF_EXIT, it tries to pop all uncheck branches from the stack(fig 3.10). The verification process will stop here since it knows the stack is empty. As a result, only the first 4 instructions in the exploit are verified while the rest 36 remain unchecked.

Fig 3.10 Evaluation of instruction BPF_EXIT, from /kernel/bpf/verifier.c




Fig 3.11 regs definition and __bpf_prog_run(), from /kernel/bpf/core.c
After verification, eBPF runs the program through __bpf_prog_run() in core.c where eBPF instructions are translated to machine instructions using a jump table. Notice the type of regs here is u64. Using the same first two instructions in exploit.c, the sign extension occurs when we evaluate the first instruction BPF_MOV32_IMM. More specifically, it happens when we run DST = (u32)IMM in line 350:
- On the right hand side,
IMMis equivalent toinsn->imm. imm is a signed 32-bit integer defined inbpf_insn(fig 3.2). HereIMM = 0xFFFFFFFF. We cast it to an unsigned 32-bit integer which is still0xFFFFFFFF. - On the left hand side,
DSTis defined asregs[insn->dst_reg], which is an unsigned 64-bit integer. When we letDST = (u32) IMM, sign extension applies andDSTbecomes0xFFFFFFFFFFFFFFFF.
Now if we evaluate the second instruction JMP_JNE_K, DST becomes not equal to IMM since 0xFFFFFFFFFFFFFFFF != 0xFFFFFFFF. This is different from what we have seen in the verifier. As a result, the jump is taken and the program continue to run the malicious instructions from line 5 onwards.
3. Explanation for the Exploit #
Fig 3.13 Data flow in the exploit
As mentioned earlier, eBPF uses shared memory for the kernel program to communicate with user applications. If we think about this carefully, this could be a potential channel for us to pass instructions to the kernel and to sneak kernel information to the outside. We shall soon see how the exploit uses this eBPF map to complete arbitrary kernel read/write in a short while.
To put it simply, the exploit comprises two parts: an eBPF filter programming running in the kernel and a helper program running in the user space. The attack can be generalised into the following steps:
exploit.ccreates a eBPF map of size 3 usingbpf_creat_map()and loads the eBPF instructionschar *proginto the kernel usingbpf_prog_load().The eBPF instructions serve as a agent which takes commands from the map and perform read/write in the kernel space accordingly. The layout of the map is defined as follows:
Index of eBPF map To read from kernel To get the current frame pointer To write to kernel 0 (opcode) 0 1 2 1 (address) Target address 0 Target address 2 (value) (Content at the address) 0 0 To trigger a read/write operation,
exploit.cfirstly store the parameters in the map usingbpf_update_elem(). It will then callwritemsg()which sends a few dummy packets to the socket and force the eBPF program to run.
Fig 3.14 __update_elem() from exploit.c
Given the helper tools above, now we can get the address of the current frame pointer by instructing the BPF program to perform opcode 1. The return value is stored in the map at index 2.

Fig 3.15 __get_fp() from exploit.c
After obtaining the frame pointer, it will be used to find the pointer of
task_structin the kernel stack(fig 3.16), which is inside a struct namedthread_info. Since the stack size is 8KB, masking out the least significant 13 bits will give the address of thread_info. Hence, the value read from the address ofthread_infowill be the address fortask_struct *task.
Fig. 3.16 pwn() from exploit.c

Fig 3.17 struct thread_info, from /arch/ia64/alpha/include/asm/thread_info.h
Using the address of
task_struct, we will be able to obtain the address of struct cred base as it is part oftask_struct. In the struct cred, there will be auid_t uidwhich can be set to0base on the offset from the address ofstruct cred. When thisuidis set to0, the process will be able to run its program with root privileges.
Fig 3.18 pwn() from exploit.c
The Patch #
1. Official Kernel Patch #

Fig4.1. Patch on verifier.c
To resolve the inconsistent execution paths between the verifier and __bpf_prog_run(), the patch forces to convert any immediate in BPF_MOV or BPF_X to the type of u64 at the verification stage. As such, malicious payload that tries to read or write to kernel memory space will always be detected before it runs.
More specifically, when the verifier reads the s32 immediate value from the instruction struct i.e. insn->imm, the value is firstly casted to u32 and then passed to __mark_reg_known() as an u64 parameter. The sign-extended u64 immediate value is stored in its various possible sign/unsigned forms in the register. This ensures all conditional checks will use the sign-extended form of imm for comparison.
2. Our Implementation #
Given the inspiration from the official patch, we also developed our own implementation which is simpler but still effective.
Fig 4.2 Patch implementation (Casting immediate value to unsigned 64 bits)
From the source analysis, the vulnerability of the program is due to the sign extension of the immediate value failing the comparison of the value stored in the register and immediate value. Hence, in order to prevent this bug from being exploited, we ensure that any 32 bit signed immediate value is casted to unsigned 64 bit immediate value before storing and using it for comparison as shown in Fig 4.2. With the implemented patch, the immediate value will always be sign extended when it is evaluated in the verifier.
Fig 4.3 Exploit runs successfully before the patch

Fig 4.4 Exploit.c Demo with our patch implementation
To demonstrate, before applying the patch, the exploit was done successfully after running the exploit.c(fig 4.3). This can be done as the kernel address for the frame pointer is leaked to find the top stack pointer thread_info. The task_struct address (0xffff880074c4c600) is found from an offset from the top stack pointer while the address of the uidptr (0xffff88001d5b0604) can be found from an offset from the struct cred which is within the task_struct. After calling the id command, the uid has been successfully set to 0, resulting in a local privilege escalation.
After re-compiling the kernel with our patch implementation, another attempt to execute the exploit.c was made. Instead of obtaining the root shell, an error error: Permission denied as shown in Fig 4.4 was thrown demonstrating that the exploit has failed. This is because the verifier now compares the sign-extended value 0xFFFFFFFFFFFFFFFF in BPF_REG_9 with the immediate value 0xFFFFFFFF when verifying the second eBPF instruction BPF_JMP_IMM. This results in a jump on not equal and the rest of the malicious eBPF payload is checked against by the verifier. Hence, the exploit will be effectively stopped from running.
References #
BFP Source Code in Linux Kernel
CVE-2017-16995 Patch Status on Ubuntu